---
> [!NOTE] 目次
```table-of-contents
title:
minLevel: 0
maxLevel: 0
includeLinks: true
```
---
> [!NOTE] リスト掲載用文字列
- [無料で日本語・手書き・縦書きもテキスト化できる国立国会図書館のWindows・Mac・Linux向けOCRアプリ「NDLOCR-Lite」](https://gigazine.net/news/20260225-ndlocr-lite/)【GIGAZINE】(2026年02月25日)
---
> [!NOTE] この記事の要約(箇条書き)
- 国立国会図書館NDLラボが、デジタル画像からテキストデータを生成するOCRアプリ「NDLOCR-Lite」を公開しました。
- 「NDLOCR-Lite」は、GPU不要で一般的なPCで動作する軽量版で、Windows、Mac、Linuxに対応しています。
- 日本語、英文、手書き文字のテキスト化を実験的にサポートしており、単一画像、切り抜き、フォルダ内の一括処理、画面キャプチャにも対応します。
- 抽出されたテキストはJSON、TXT、XML、TEI形式などで保存されます。
- 記事の冒頭では、GIGAZINEのサーバー運営が価格高騰で苦境にあり、読者に対し月額825円または1回900円からの寄付による支援を求めています。
> [!NOTE] 要約おわり
---
[レビュー](https://gigazine.net/news/C12/)
[](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/00.png)
国立国会図書館の **[NDLラボ](https://lab.ndl.go.jp/)** は、デジタル画像からテキストデータを作成できる **[OCR](https://ja.wikipedia.org/wiki/%E5%85%89%E5%AD%A6%E6%96%87%E5%AD%97%E8%AA%8D%E8%AD%98)** アプリ「 **NDLOCR-Lite** 」を公開しました。以前に公開していた「NDLOCR」の軽量版を目指して開発されており、一般的なPCでGPUを必要とせず使用可能です。
**NDLOCR-Liteの公開について | NDLラボ**
**[https://lab.ndl.go.jp/news/2025/2026-02-24/](https://lab.ndl.go.jp/news/2025/2026-02-24/)**
**GitHub - ndl-lab/ndlocr-lite: NDLOCR‑Lite application repository (including source code)**
**[https://github.com/ndl-lab/ndlocr-lite](https://github.com/ndl-lab/ndlocr-lite)**
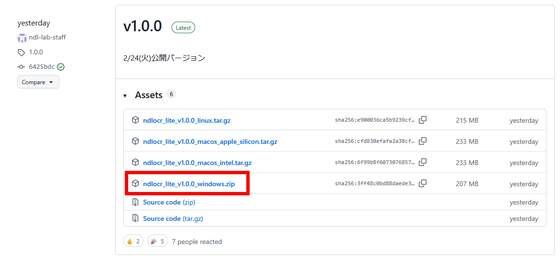
NDLOCR-Liteを使用するには **[配布ページ](https://github.com/ndl-lab/ndlocr-lite/releases)** にアクセスし、使用する環境に合わせた最新版を選択してダウンロードします。今回はWindows版を使用します。
[](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2014.png)
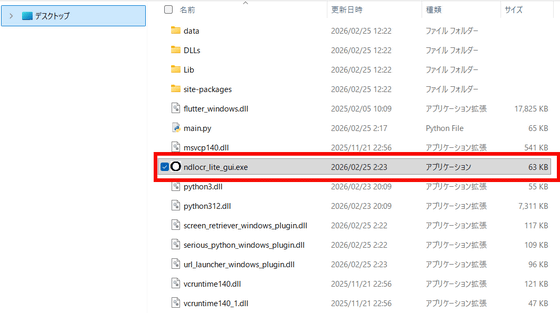
ダウンロードしたZIPファイルを展開したら、「ndlocr\_lite\_gui.exe」を起動。
[](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2017.png)
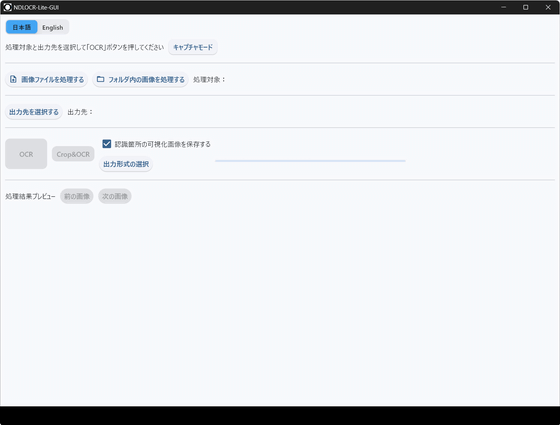
NDLOCR-Liteが起動しました。
[](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2018.png)
「画像ファイルを処理する」をクリックしてテキストを抽出したい画像を選択します。今回は電子書籍「 **[アニメ監督のお仕事とは?: アニメ業界インタビューまとめ](https://www.amazon.co.jp/exec/obidos/ASIN/B0BK1MYGCG/gigazine-22)** 」のキャプチャ画像からテキストを抽出してみます。
[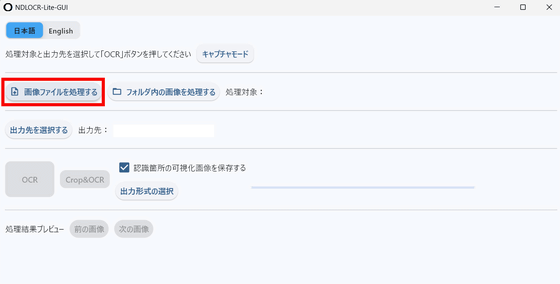](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2021.png)
画像ファイルを選択して「開く」をクリック。
[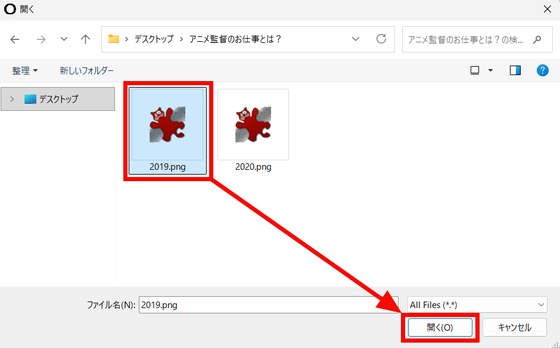](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2022.png)
ファイルのパスが選択されているのを確認したら「出力先を選択する」をクリック。
[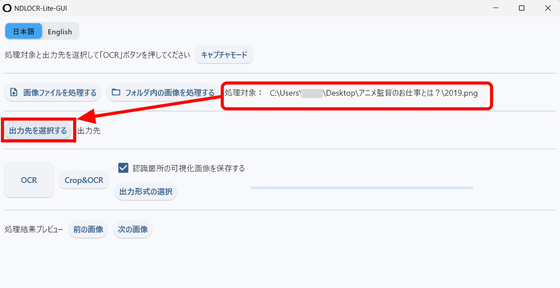](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2023.png)
抽出したテキストファイルなどを保存する出力先フォルダを作成したら「フォルダーの選択」をクリックします。
[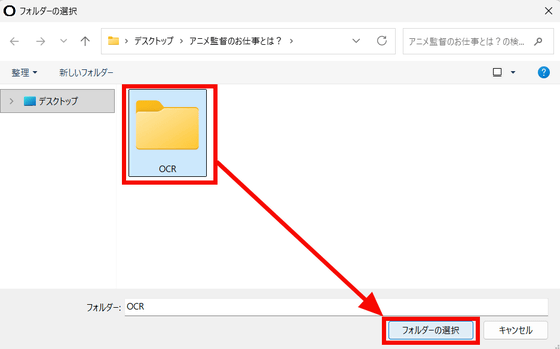](https://i.gzn.jp/img/2026/02/25/ndlocr-lite/snap2024.png)
画像と出力先を選択したら「OCR」をクリックしてテキスト抽出開始。
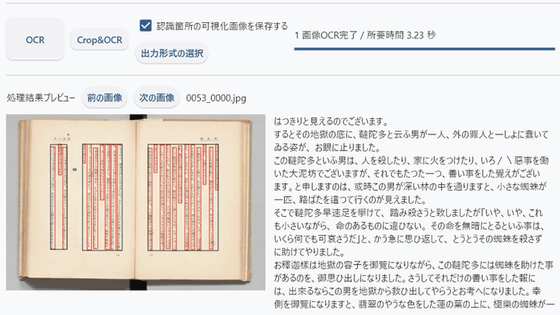
1.24秒で画像のOCRが完了しました。画面下部にはプレビューが表示されています。
出力先フォルダには、JSON形式、TXT形式、XML形式、TEI形式、プレビュー画像が保存されていました。TXT形式のファイルを開いてみます。
以下のように画像から文字起こしされていました。なお、改行は画像と同じ場所になっています。
元画像(左)と抽出したテキスト(右)を比較すると以下のような感じ。
次に、画像を選択した状態で「Crop&OCR」をクリック。
読み込んだ画像が表示されるので、画像の上をドラッグして青い四角でテキストを抽出したいエリアを選択します。選択したら「切り抜きOCR」をクリック。
選択部分のテキストが抽出されました。なお、切り抜きOCRのデータはテキストファイル等で保存されません。
また、フォルダ内の画像をまとめて処理することもできます。「フォルダ内の画像を処理する」をクリック。
処理するフォルダを選択して「フォルダーの選択」をクリックします。
「OCR」をクリック。
複数の画像が処理されました。「次の画像」をクリックすることでプレビューを切り替えることができます。
出力先フォルダには複数画像がそれぞれの形式で書き出されていました。
そのほか、画像だけではなく画面上を直接キャプチャしてテキスト化することもできます。「キャプチャモード」をクリック。
画面上の画像等からテキスト化したい部分をドラッグして囲みます。
キャプチャできたら「OCR実行」をクリック。
キャプチャ部分をテキスト化することができました。ただし、一部が途切れていたり向きがズレていたりすると正しくテキスト化されないので注意が必要です。
NDLOCR-Liteの特徴として、NDLOCRと比較してGPU不要で軽量になったことに加えて、NDLOCRが不得意としていた英文や手書き文字等についても実験的に対応しているとのこと。試しに、アメリカ内国歳入庁(IRS)から届いた **[納税者番号「EIN」の書類](https://gigazine.net/news/20250817-ein-application/)** を撮影した写真からテキスト抽出してみたところ、英文も問題なくテキスト化できました。
NDLOCR-Liteは、国立国会図書館が **[CC BY 4.0ライセンス](https://creativecommons.org/licenses/by/4.0/deed.ja)** で公開しています。また、GPUを必要とする **[NDLOCR](https://github.com/ndl-lab/ndlocr_cli)** についても引き続き利用可能です。
**GitHub - ndl-lab/ndlocr-lite: NDLOCR‑Lite application repository (including source code)**
**[https://github.com/ndl-lab/ndlocr-lite](https://github.com/ndl-lab/ndlocr-lite)**
この記事のタイトルとURLをコピーする
**・関連記事**
**[AIのOCR能力を競わせて評価する「OCR Arena」 - GIGAZINE](https://gigazine.net/news/20251210-ai-ocr-arena)**
**[AIくずし字認識アプリ「みを(miwo)」を使ってみた - GIGAZINE](https://gigazine.net/news/20210831-miwo)**
**[高速かつ高精度な文字認識AIモデル「Mistral OCR」が登場、LaTeXで書かれた数式や図表入りPDFのレイアウトを崩さずマークダウン形式で出力できてJSONへのデータ抽出も簡単に - GIGAZINE](https://gigazine.net/news/20250307-mistral-ocr)**
**[業界最高水準の文字認識AI「GLM-OCR」をZ.aiがオープンソースで公開、ローカル環境でも動作できるほど軽量 - GIGAZINE](https://gigazine.net/news/20260204-z-ai-glm-ocr)**
**[表の画像からテーブルを自動で作成してくれる「Extract Table」 - GIGAZINE](https://gigazine.net/news/20210929-extract-table)**